來源:智能鏈

近日百度原首席科學家吳恩達發文宣布離職百度。百度也宣布進一步架構深度整合,將包括NLP、KG、IDL、Speech、Big Data等在內的百度核心技術,組成百度AI技術平臺體系(AIG),任命百度副總裁王海峰為AI技術平臺體系(AIG)總負責人,同時晉升為Estaff成員,轉向百度集團總裁和首席運營官陸奇匯報。
王海峰是自然語言處理(Natural Language Processing,簡稱NLP)領域的權威科學家,是該領域最具影響力的國際學術組織ACL 50多年歷史上唯一出任主席(President)的華人,同時也是截至目前最年輕的ACL Fellow。
此外,王海峰博士還是中文信息學會理事、中文信息學報編委、中國計算機學會(CCF)高級會員、國家自然科學基金委員項目評審會評審專家組成員。
此前2月5日在AAAI2017上,王海峰博士應邀做了題為《百度的自然語言處理應用(Natural Language Processing at Baidu)》的報告,全面梳理百度這些年在NLP領域的工作成果。
以下為演講全文:
大家好,我是來自百度公司的王海峰。在介紹百度NLP工作之前,我想先談談語言對于AI意味著什么。
思考和獲得知識的能力成就了今天的人類,這種能力需要通過語言來找到思考的對象和方法,并外化為我們看、聽、說和行動的能力。而語音、視覺、行為和語言等正是現在AI領域的重要研究內容。
相對于看、聽和行動的能力,語言是人類區別于其他生物最重要的特征之一。語言是人類思考的載體,通常我們的思考語言是母語。當我們學習外語時,老師希望我們要努力使用外語來思考。另一方面,從人類歷史之初,知識就以語言的形式進行記錄和傳承,用來書寫語言的工具不斷改進:從甲骨到紙張,再到今天的互聯網。
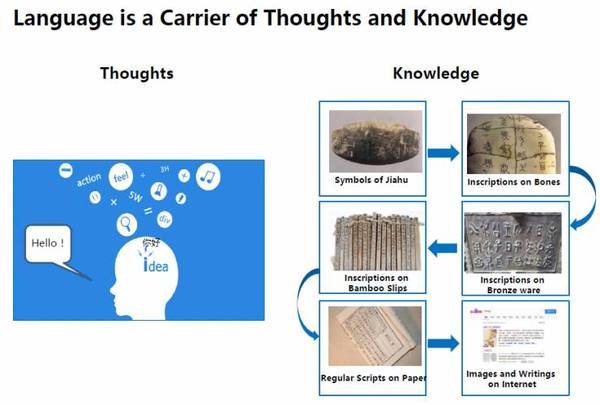
所以我們說,語言是思想和知識的載體,而對語言的處理和理解就顯得尤為重要。計算機領域中自然語言處理(Natural Language Processing: NLP)的目的,就是讓計算機能夠理解和生成人類語言。
在百度,基于大數據、機器學習和語言學方面的積累,我們研發了知識圖譜,我們分析理解query、篇章及情感,我們構建了問答、機器翻譯和對話系統。NLP技術已經應用在百度的眾多產品上,比如搜索、Feed、o2o和廣告等。
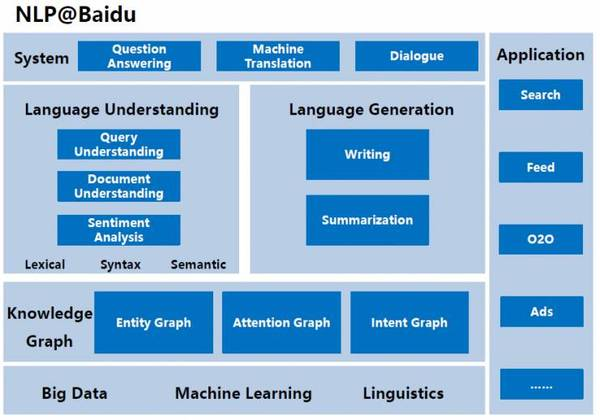
知識圖譜
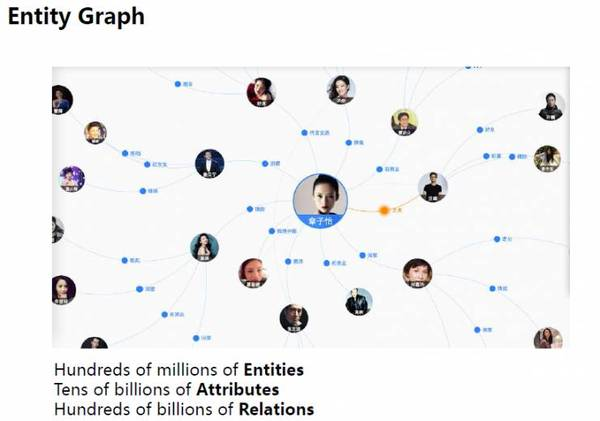
基于不同的應用需求,我們建立了三類知識圖譜,包括實體圖譜(entity graph)、關注點圖譜(attention graph)和意圖圖譜(intent graph)。
在實體圖譜里,每一個節點都是一個實體,每個節點都有幾個屬性,在這個例子中,節點之間的連接是實體之間的關系。目前我們的實體圖譜已經包含了數億實體、數百億屬性和千億關系,這些都是從大量結構化和非結構化數據挖掘出來的。
這兒有一個例子,搜索的問題是:竇靖童的爸爸的前妻的前夫。
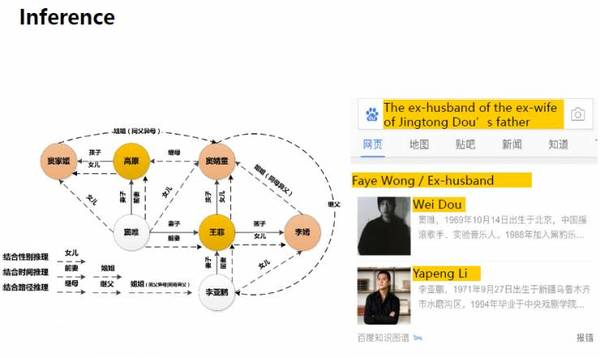
這句話里包含的人物關系是非常復雜的,然而,我們的推理系統可以輕松地分析出各實體之間的關系,并最終得出正確答案。
除了實體圖譜之外,我們還建立了關注點圖譜和意圖圖譜,稍后我在篇章理解和對話系統的部分將給大家介紹。
語言理解
Query理解
基于實體識別、語法和語義分析等技術,我們研發了query、篇章和觀點分析和理解技術。接下來,我將進一步介紹query理解。我們結合“依存句法分析(Dependency Parsing)”和“語義理解(Semantic Understanding)”來實現query理解。
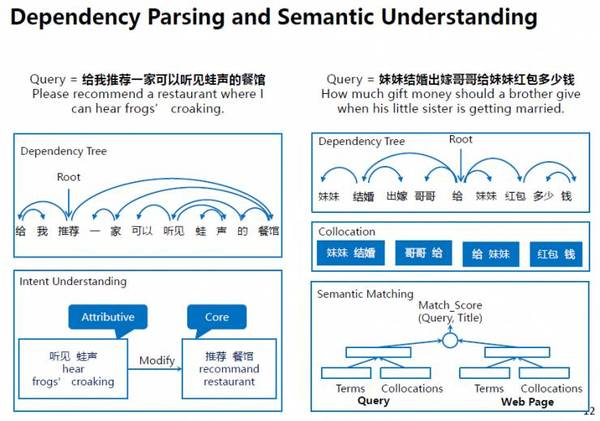
在上圖所示例子里,左邊用戶輸入的query是“給我推薦一家可以聽見蛙聲的餐館”。我們使用了依存句法分析技術,來分析該語句的句法結構,幫我們找到句子里的各個組成成分。比如,“推薦、餐館”是核心成分,表明了用戶的主要意圖,而“聽見、蛙聲”是修飾成分,對用戶的意圖進行了修飾和限定。
右邊用戶輸入的query是“妹妹結婚出嫁哥哥給妹妹紅包多少錢”,說明我們是如何提升query和網頁之間的語義匹配(semantic matching)。首先,我們基于依存句法分析識別出這條query中的搭配,這種詞語搭配相比于單個詞語更能夠準確表征query的語義,進而可以將其應用到query與網頁的精確匹配中。
另外,基于語義理解技術,我們可以理解一個query的語義,實現語義級的搜索而不僅僅是字面匹配。
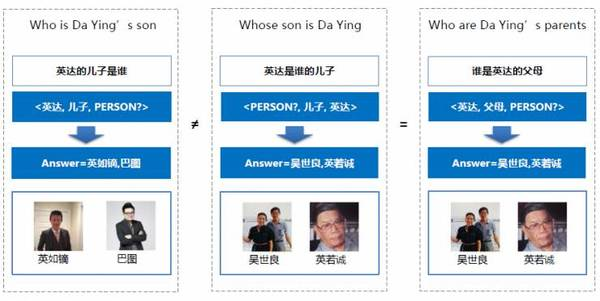
上圖里前兩句話是:
英達的兒子是誰
英達是誰的兒子
這兩個句子里包含著相同的詞語,只是詞語的語序不同。如果使用傳統的基于關鍵詞的搜索技術,我們將會得到幾乎相同的搜索結果。然而,經過語義理解技術的分析,我們可以發現這兩個句子的語義是完全不一樣的,相應地就能從知識圖譜中檢索到完全不同的答案。
還有第三句話:
誰是英達的父親
在字面上來看,這跟第二個句子并不一樣,但是經過語義理解技術,我們發現這兩個句子要找的是同一個對象,所以我們可以從知識圖譜中檢索到相同的答案。
我們同樣開發了基于深度學習的語義理解技術,實現了一個基于深度學習來計算query和文本語義關聯。我們使用了超過1000億的用戶數據來訓練模型,對于一個query,包括用戶點擊過的正例和未點擊的負例。我們使用了BOW、CNN和RNN模型來學習語言的語義表示。為了提升模型對語義的表征,我們融合進多種句法和語義結構,將“依存關系結構”融合進模型中。

下圖是在不應用深度學習模型時的搜索結果,結果是不相關的。
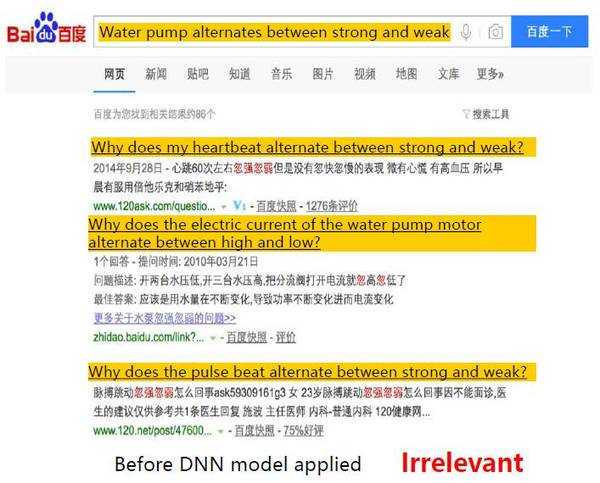
應用了深度學習模型之后,搜索結果里的前3個都是相關性的。從2013年開始應用DNN模型至今,我們已經對這個模型進行了幾十次的升級迭代,DNN語義特征是百度搜索里非常重要的一個特征。

篇章理解
用戶獲取信息另一個重要渠道就是Feed,里面的資訊是個性化的,這其中,篇章理解技術發揮了重要作用。現在,我來為大家介紹一下我們在篇章理解方面的一些工作。
我們給文檔打上各種各樣的標簽,包括:主題、話題和實體標簽。主題標簽表示抽象的概念,話題標簽表示具體發生的事件,實體標簽表示人、地點等實體信息。這些標簽,從不同角度描述一個文檔的內容,以滿足不同應用需求,并與不同的query相關聯。
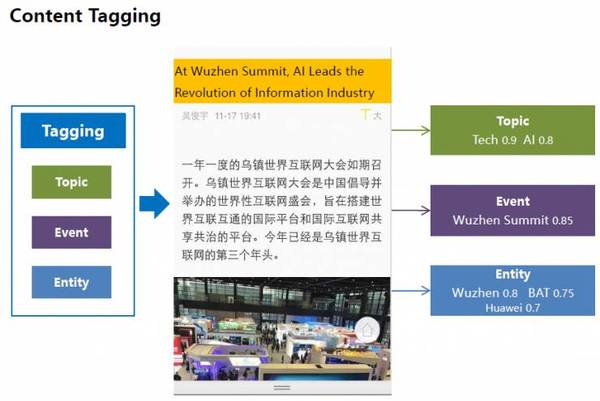
融合了話題標簽和實體標簽,我們形成了關注點標簽圖譜。這種關注點標簽能更好地描述用戶與文檔之間的關系,因為它能同時對用戶和文檔進行表征。我們也在不同類型的關注點標簽之間建立關系,這樣我們可以對用戶關注點進行推理和計算。在下圖所示例子里,“AI”話題與“科技”、“VR”等話題及“烏鎮峰會”等事件關聯在一起。
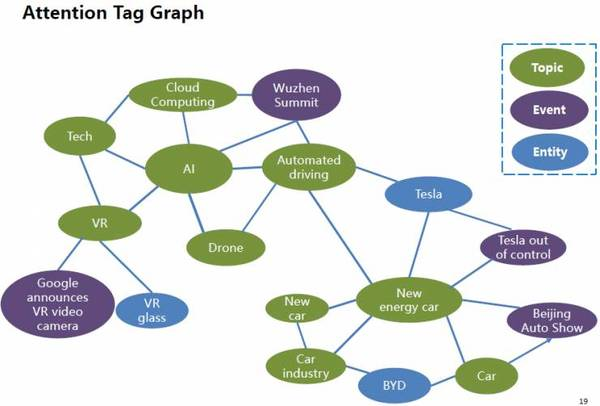
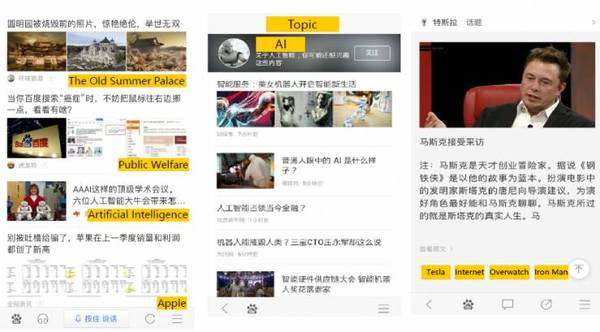
以下是關注點標簽圖譜應用在百度Feed里的一個例子,在左圖中,標簽表征了文章里的內容,用戶可以點擊標簽進入到以一個話題為主題的聚合頁(第二張圖)。然后第三張圖是基于關注點標簽圖譜進行個性化推薦,更能契合用戶的關注點,帶來了更高的點擊率。
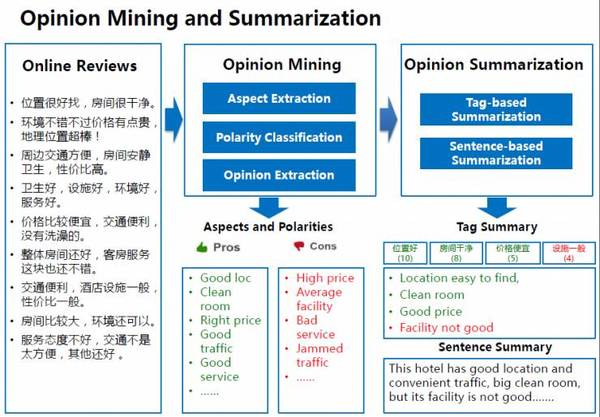
情感分析是篇章理解里另一個有趣的話題。情感分析技術也被稱為“觀點挖掘”(opinion mining),用來分析人類對各種對象(比如產品、組織機構等)的觀點、情感和情緒。下面是我們在“觀點挖掘”和“觀點摘要”方面的一些工作。以“酒店評價”為例子,我們從已有的在線評論數據中抽取評論句,并進而從中提取用戶觀點。基于這些觀點,我們可以生成標簽級的觀點摘要和句子級的觀點摘要。我們也可以以此為基礎來進行酒店推薦。
這里是一些關于情感分析應用于百度產品的例子,觀點自動摘要技術為用戶提供觀點標簽,在左邊的例子里,我們提供了關于“八達嶺長城”的多個維度的評價,在右邊的例子里,我們在觀點分析的基礎上為用戶提供了精煉的推薦理由。

語言生成
自動新聞寫作
自動新聞寫作,即從結構化和非結構化數據里生成新聞文章。這里面共涉及四個步驟:
數據分析(data analysis):確定要生成文章所需包含的關鍵信息
文章規劃(document planning):確定生成文章的內容和結構
微觀規劃(micro-planning):生成單詞、語句、段落和標題
文章實現(surface realization):生成最終的文章內容
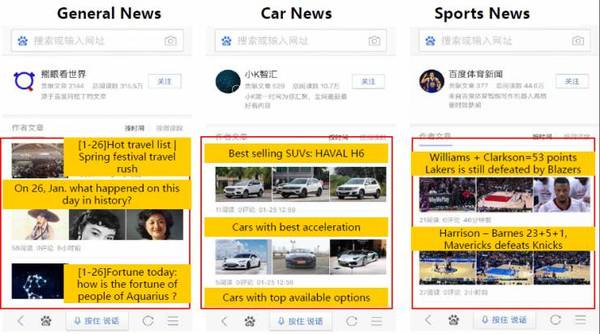
以下是我們自動寫作的新聞。左邊第一個例子,是一般的新聞,第二個是生成汽車領域的新聞,第三個是體育新聞,目前我們的自動寫作系統已經完成了數千篇文章的寫作,在百度Feed產品中得以被數百萬的用戶閱讀。
AI 籃球解說員
我們的AI解說系統,可以像人類解說員一樣,生成一場比賽的實時解說并與觀眾互動。這里面的實現主要包括四個步驟:
信息搜集(information gathering):從網上實時收集和提取比賽的關鍵信息
生成結構化數據(structured data generation):基于不同消息源的比賽信息,生成結構化解說數據
比賽場景推理(game scene inference):基于比賽數據(比如得分和統計),推斷出現場比賽場景
生成直播解說(live commentary generation):基于解說模型,生成直播解說
以下是我們AI解說員生成的關于一場真實比賽的解說。
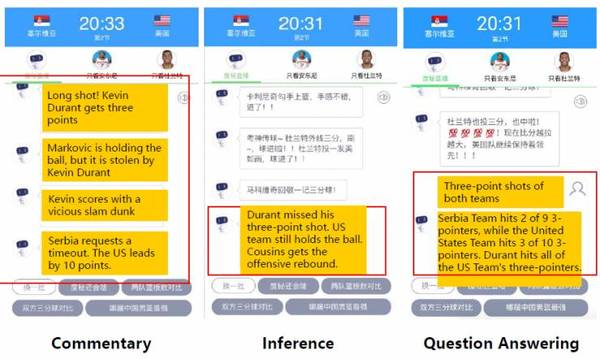
中間這個圖,顯示出這個AI解說員也可以進行推理,它在其中的一段解說中提到“考辛斯搶到了進攻籃板”,“進攻籃板”這個短語表明我們的AI解說員通過已有的知識了解到考辛斯所在球隊目前處于進攻階段,經過推理從而得出“進攻籃板”的結論。
最右邊的例子,說明了我們的AI解說員除了解說,還可以同時回答多個觀眾的提問,而這是人類解說員所不能做到的。
詩歌生成
語言生成技術還可以應用在另一個方面:中國詩歌生成,而且文采并不比一般詩人差。中國詩歌有超過兩千年的歷史,是中國文化重要的組成部分,但對普通人來說,作詩還是很有難度的。
我們提出了兩步生成中國詩歌的方法:首先對每一行詩的主題進行規劃,然后進行具體詩句的生成。
舉個例子,如果用戶想要寫一首和春天有關的詩,那么詩歌規劃模型就會首先生成一個內容概要,包括春天,桃花,燕和柳這四個主題,然后由RNN模型根據這四個主題生成四句詩,來完成整首詩歌的創作。
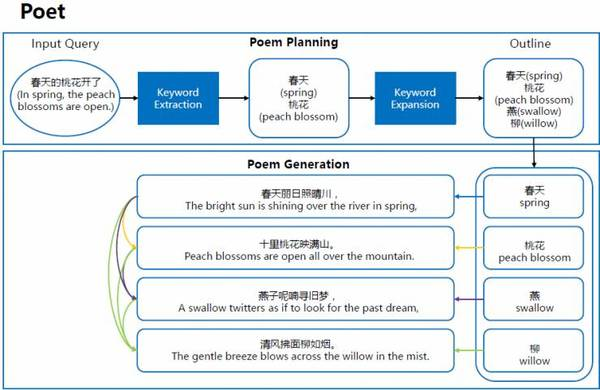
在下面展示的這三首詩中,中間這首是由AI詩人完成的,而其他兩首的作者都是中國古代詩人(白居易,劉因)。有意思的是,在我所詢問的人中,多數人都無法分辨出這三首詩中到底哪一首出自AI詩人之手。歷史學者和《中國詩詞大會》嘉賓蒙曼教授也說,“這個人工智能詩人是詩壇小超人,能和人類詩人一樣在詩中表達感情色彩。”

文本摘要
另外,我們還研發了文本摘要技術。具體來說,包括一般的文摘(general summarization)和基于query的文摘(query summarization)如下表中展示的具體過程:
文本分析(document analysis):分析文本結構
句子排序(sentence ranking):通過句子的表層含義和深層含義來實現對句子的排序
句子選擇(sentence selection):從句子重要性、句子間是否連貫,以及去除冗余等角度來考慮如何選擇文摘中的句子
生成文摘(generation):把選定的句子進行壓縮,并整合成最終的結果
一般文摘和基于query的文摘這兩種技術的不同之處在于“句子排序”環節。在基于query的文摘里,我們對query的特征進行計算,以使得最終文摘體現出與query的相關性。

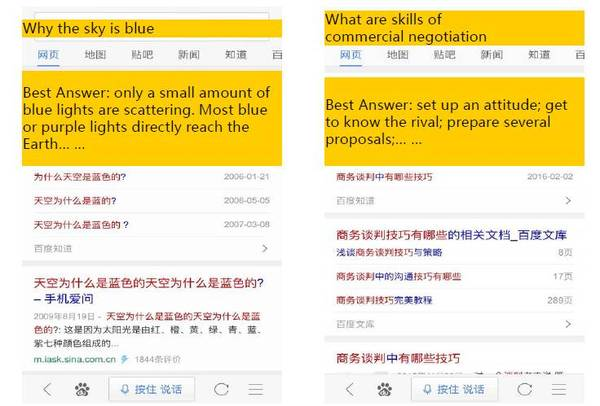
這里有兩個文摘在搜索結果中體現的例子。左圖顯示,輸入query“天空為什么是藍的”,系統可以挑選出與這句話相關的網頁,從中抽取出摘要并顯示出來;右圖中的例子也是同樣道理。
自然語言處理應用系統
下面介紹三種自然語言處理的應用系統:問答、機器翻譯和對話系統。
問答
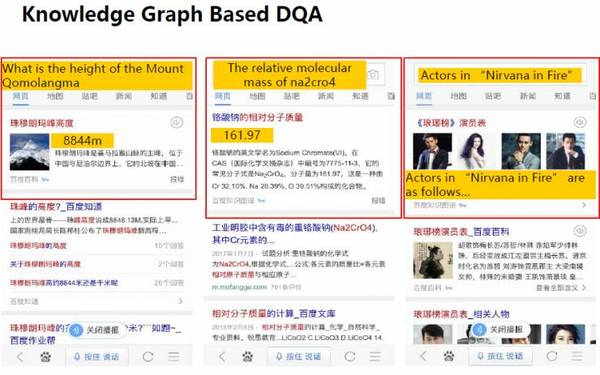
當用戶在提出問題時,系統可基于知識圖譜加以回答。
比如,當用戶在搜索框內輸入“珠穆朗瑪峰高度”時,網頁就會出現有關珠穆朗瑪峰的圖片和其高度說明;用戶也可以輸入“瑯琊榜演員表”,那么百度搜索網頁上就會直接出現《瑯琊榜》的演員表及其照片。
除了基于知識圖譜的問答,我們還設計了一種基于網絡的深度問答系統。該系統對網頁搜索結果中的內容進行分析,并識別用戶問題中的關鍵詞。然后系統會從網頁中分析出和問題相關的文檔,從中抽取出問題的答案,并展現在搜索結果頁的最上方。
比如,用戶可以搜索“糖尿病患者應該吃什么”,那么系統則會回答“飲食建議、飲食禁忌”等內容。這些信息來自于網上的醫療領域數據,經過信息挖掘和匹配,生成答案呈現在用戶面前。

機器翻譯
如今,基于神經網絡的機器翻譯十分火熱,不過,傳統的機器翻譯方法仍有價值。所以,我們的系統結合了新舊四種方法:
神經網絡機器翻譯(neural MT)
基于規則的機器翻譯(rule-based MT)
基于實例的機器翻譯(example-based MT)
基于統計的機器翻譯(statistical MT)
2015年5月,百度將神經網絡機器翻譯技術應用到百度在線翻譯服務中,推出了全球首個基于深度學習的大規模在線翻譯系統。同年,百度還在百度翻譯app中上線了離線翻譯功能,讓用戶在沒有網絡連接的情況下也可以使用翻譯服務。
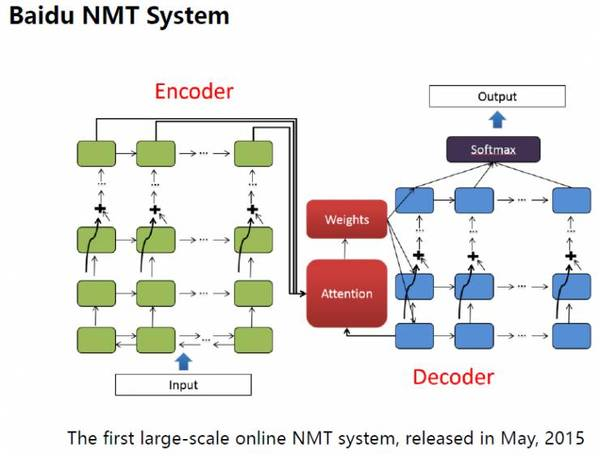
目前,百度翻譯已可支持全球28國語言、756個翻譯方向之間的互譯,每日翻譯次數達1億以上。
不僅如此,我們還提供多樣化的功能以滿足用戶的不同需求——除了文字翻譯,百度翻譯還能進行語音翻譯以及利用OCR技術進行圖片內容翻譯。所以,以后到國外旅行就不用擔心語言不通這個問題了。去餐館吃飯時,只要用手機照一下菜單,立刻就能將其翻譯成你所需要的語言。
同時,我們已經為超過2萬個企業和開發者提供百度翻譯API,讓他們提升自己的產品功能,為用戶提供更優質的服務。
另外,我們還把百度翻譯和百度搜索引擎結合在一起——當用戶在搜索框內輸入外語時,百度搜索引擎會自動識別出翻譯需求并將翻譯結果顯示在搜索結果最上方。
在2015年的ACL會議上上,百度的智能機器人“小度”還擔任了ACL終身成就獎獲得者李生教授的同聲傳譯。在問答環節,小度將現場觀眾提問的英文問題立刻翻譯成中文,然后將李教授的中文回答翻譯成英文呈現給觀眾。現場觀眾(大部分是自然語言處理方面的專家學者)對小度的表現大為贊嘆,并對機器翻譯目前的成就感到欣喜。

對話系統
接下來,我會介紹百度的對話系統。該對話系統能與用戶進行多輪交互(multi-turn interaction)。首先,用戶的輸入經過自然語言理解(NLU)模塊,進入對話管理系統。該系統識別出當前的對話狀態(dialogue state),并確定下一步的對話行為(dialogue action)。我們的對話策略( policy) 模塊,包含通用模型和領域模型,即前者負責處理通用的交互邏輯,后者則處理特定領域的交互邏輯。最后,該系統會為用戶生成交互回復。
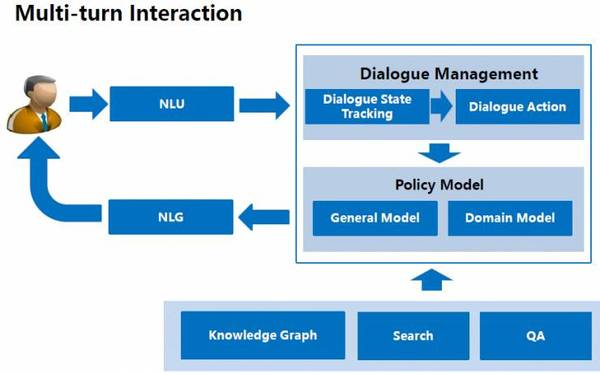
這里有一個例子,是高考之后,百度智能助理“度秘”和用戶之間的對話。當用戶問:“我能進入哪所大學?”度秘會反問他問題,以進一步了解情況。度秘問:“你是文科還是理科?”對方回答:“理科”。度秘接著問:“你考了多少分?”他回答:“620 分。” 度秘隨即根據這些信息,推薦適合他填報志愿的學校。在 2016 年的全國高考期間,度秘處理了480 萬百用戶的 3000萬個請求。

接下來我要談一談我們的意圖圖譜技術。與我之前講過的實體圖譜不同,意圖圖譜的節點代表一個個意圖節點。這些“意圖”之間的關系包括需求澄清(disambiguation)、需求細化(depth extension)、需求橫向延展(breadth extension )等。在下圖所示例子中,當“阿拉斯加”的意思是“阿拉斯加州”時,與之關聯的意圖是城市、旅游等信息。當“阿拉斯加”的含義是“阿拉斯加犬”時,它延伸的意圖是寵物狗、寵物狗護理,以及如何喂食等。

這樣的意圖圖譜可用于人機對話系統當中,下面讓我們來看一個度秘基于意圖圖譜的用戶引導例子。
用戶想要查詢關于“金毛”的信息,基于意圖圖譜,度秘提供給用戶關于金毛的一般信息;接著進入第二輪,用戶點擊了“我想要一只金毛”的選項,度秘便可以猜測用戶接下來會想要知道“如何喂養一只金毛”、“什么樣的人適合養此類犬”等信息,并將這些引導項展現給用戶。然后用戶點擊了“喂養一只金毛容易嗎”的選項。對話進行到此輪,用戶的需求基本被滿足了。
以上,我介紹了百度在NLP領域的諸多工作,包括知識圖譜、語言理解、語言生成和幾個應用系統(包括問答、機器翻譯和對話),我們已經將這些技術應用在百度的產品當中,另外我們也通過平臺化的方式對更多產品進行支持,比如我們開發的NLPC(NLP Cloud)平臺,現在已經可以提供20多種NLP模塊,每天被調用超過1000億次。
最后我想說的是,我們今天在NLP領域里的探索和追求,將會對我們逐步實現人類的人工智能夢想產生至關重要的影響。謝謝大家。



