來源:砍柴網
Zippo能不能帶上飛機?搜索最新版《射雕英雄傳》,會看到83經典版嗎?科比和詹姆斯誰厲害?……11月8日召開的AI World2017世界人工智能大會上,這些問題,都在百度副總裁、AI技術平臺體系總負責人王海峰的演講中,找到了答案。
在題為“匯聚知識,理解世界”的演講中,王海峰用實例生動展現了百度知識圖譜的能力和應用價值。他認為,知識是AI進步的階梯,匯聚知識的人工智能會變得更強大。百度知識圖譜依托海量的互聯網數據,綜合運用語義理解、知識挖掘、知識整合與補全等技術,提煉出高精度知識,并組織成圖譜,進而基于知識圖譜進行理解、推理和計算,幫我們更好地從客觀世界中挖掘、獲取,沉淀知識,理解真實世界,讓復雜的世界更簡單。

(百度副總裁王海峰)
王海峰表示,目前,百度知識圖譜已經擁有數億實體、數千億事實,并已廣泛應用于百度眾多產品線。
以搜索為例,傳統搜索基于關鍵詞和網頁,只是羅列出和目標關鍵詞匹配的頁面地址,用戶獲取結果需要再次篩查尋找。通過知識圖譜,用戶能夠直接得到想要的“知識”,獲得聚合的信息與服務。王海峰在演講中列舉的知識圖譜應用案例,讓現場觀眾頻頻舉起手機拍照記錄。
“人工智能已經滲透到生活、工作的方方面面,”王海峰表示,知識圖譜通過AI技術、大數據以及在與用戶互動過程中的不斷學習,匯集越來越多的知識,幫助機器更好地理解世界,讓人工智能更強大。而強大的人工智能進一步提升產品,推動產業升級,讓我們的生活變得更加美好。
以下是現場演講實錄:
各位熱愛AI以及關心AI的朋友們,各位從事AI的同仁們,大家上午好,非常感謝楊靜女士給我這個機會,和大家交流人工智能相關的話題。我的主題聚焦在AI具體領域—即知識圖譜。
我們認為,知識是AI非常重要的基石,所以,今天我專門和大家交流一下我們在知識圖譜方面的工作。
“科學技術是第一生產力”,這句話相信所有朋友都知道。從18世紀第一次工業革命開始,科學技術就把巨大的自然力和自然科學注入到生產過程中,從而大大提升了生產力,生產力又影響生產關系的變化,進而為整個社會方方面面都帶來改變。19世紀的第二次工業革命使我們進入電氣時代,20世紀第三次工業革命使我們進入了信息時代。隨著這些工業革命的發生,科技對我們越來越重要。而今天,我們非常幸運地處在第四次工業革命之中,這其中最核心的科技就是人工智能。我們看到,人工智能已經在影響我們生活的方方面面,滲透到各行各業。無論是我們想搜索信息還是瀏覽信息,還是根據地圖導航出行,或者翻譯……各行各業都在大量地應用人工智能。
我們可以清晰地看到,不管世界范圍內還是在中國,人工智能的投資、產業規模等都在迅速增長,而且可以預計未來還會高速增長。人工智能在各個領域、各個方向上都非常活躍。
總結以上所說的,我們認為,人工智能是新的生產力,是未來很長一段時間里,人類生產力提升最重要的基礎。
眾所周知,百度是從做搜索引擎開始的。差不多18年前,我們開始做搜索引擎。從做的那天開始,一些人工智能技術就在其中得到應用,比如自然語言處理技術。七八年前,我們更全面地布局人工智能,從自然語言處理開始,到語音、圖像、深度學習、機器學習、數據挖掘等等,今天,我們形成了相對完整的人工智能布局。
基礎層,是人工智能很重要的組成部分,要有大數據,強大的計算能力,還要有非常強大的算法。
而真正可以模擬人的能力,我們把它們分成兩層:感知層和認知層。我們知道,每個人通過眼睛、耳朵等來感知這個世界,所以,我們要做計算機視覺相關的圖像、視頻技術,也要做AR、VR技術,還要做和人的聽覺相關的語音技術,如語音識別等等。應該說,感知能力不僅人有,很多動物也有,甚至有的動物聽覺比人強,有的動物視覺比人強。而認知是人特有的,語言是人區別于其他動物的能力。同時,知識也是人不斷進步的重要基礎。我們除了要有認識客觀世界的知識,人和人之間還要交互,以及對人的理解,這就是認知層的技術要解決的。
在此基礎上,我們提供AI開放平臺。在百度內部,我們用平臺化的方式支持了公司大量的應用,同時也把我們的平臺對外開放,打造AI生態,最終通過產品應用為每個用戶、企業等提供服務。
假如我們要搜索一張圖片,用圖像處理技術很容易在網上找到一張相似的圖,這個圖像處理技術就能完成了。如果我們想問的問題是,白葡萄酒的營養價值,僅僅圖像處理技術就不夠了,這需要知識。百度在回答這樣一個問題時就會用到背后的知識圖譜。下面這個例子也是一樣:語音技術可以把曲子識別出來是什么,相應地在曲庫里找到歌曲,甚至專輯的封皮也能調出來,但是如果想知道這個曲子誰演奏過,僅僅語音技術就不夠了,這就需要知識以及知識圖譜的支撐。
因此,大家看到,感知層、認知層技術看似是相對獨立的,而且每個技術也有非常多的問題要繼續研究解決,但是,把它們組合在一起,尤其是賦予知識以后,我們就可以做更多的事情。所以我想說,知識是AI進步的階梯。我們每個人都知道高爾基這句話——“書籍是人類進步的階梯”,這里面包含兩方面的意思,一方面人通過讀書可以不斷地學習更多的知識,不斷地進步;同時,有了更多知識,更多能力的人也可以不斷地產生新的知識,有更多的知識可以沉淀下來、傳承下去,這個階梯也會隨之越大越高,人也可以越走越高。對人工智能來講,知識也是一樣的,有了知識的人工智能會變得更強大,可以做更多的事情,反過來,因為強大的人工智能,也可以幫我們更好地從客觀世界中去挖掘、獲取和沉淀知識,而這些知識和人工智能系統形成正循環,兩者共同進步。
我們有很多方法可以把現實的知識富集起來,通過各種算法,讓它變成一個網狀的知識圖譜,這里面的知識非常多,比個人腦子里存儲的知識都要多,同時可以有強大的網絡,成為人工智能應用的基石。
先舉個例子,這是從數據到信息、到知識、到智能的“金字塔”。比如我們看到95這個數字,我們都知道這是數字,但它意味著什么呢?如果我不給你更多的信息,你只知道它是一個數字,如果我告訴你,這是今天的PM2.5指數,那95這個數字就變成了一條有用的信息。但是如果我沒有背景知識,不知道PM2.5是95意味著什么,這個信息對我的價值也不大,95是好還是不好呢,不知道。如果這時候有知識,我知道95意味著空氣質量大概是良,這就已經是有知識了。進一步,我可以知道這個指數可以正常戶外活動,但敏感人群應該減少外出,這就是從信息到知識到智能的過程。
這是百度知識圖譜。最下面一層,我們要有基礎的存儲、運算和服務能力。百度的知識圖譜從非常多的海量數據里挖掘出來,包括互聯網上的數據、行業數據,也包括日志數據等等,再進行挖掘、歸一、融合。同時,圖中一個個節點要建邊,最終形成通用知識圖譜、行業知識圖譜。在這些基礎之上的巨大圖譜,會有基本的算子去查詢、標注、計算、推理、預測等,每一個產品會調用這些算子訪問圖譜,從而完成特定的能力。
這樣講還比較抽象,給大家看一個圖。這是百度龐大的知識圖譜里一個很小的局部。我們隨便從中間看一個節點,比如《中國有嘻哈》,會發現很多事實可以連接到這個節點上,比如它相關的演員、音樂的類型,辦這個節目的愛奇藝等等。經過幾次大家發現會關聯到很遠,右邊是關聯到中國諾貝爾獎得主屠呦呦,左邊也關聯到其他很多人。知識圖譜包含大量的知識,在不同的應用中會起作用。當然,這里面每個節點,遠遠大于我此刻所展現出來的,如果這個屏更大,能給大家展現更多。

回到抽象的部分,看看我們這個知識圖譜到底有多大。這里面的每個節點可以理解為一個實體,不管是人、物還是實體,大概有幾億個,實體和實體之間會有很多邊,一個實體可能會有幾十個、幾百個、幾千個邊,這是組合關系,非常多。每個邊構成一個事實,比如《中國有嘻哈》誰參加了這個演出就是一個事實,誰舉辦了它又是一個事實。現在百度知識圖譜里這個事實的量已經有千億個。同時,我們支持基于圖譜的動態計算,包括幾十個應用場景,每天有幾百個數據流同時在工作,都支持秒級更新,可以多層次地查詢。
下面舉一個通用知識圖譜的例子。這里有一段百度百科里的文字,通過自然語言分析理解,可以把這段文字抽取成一個圖譜。比如銀河系會和太陽、地球等連接,會有很多邊,這是抽取出來的一個通用圖譜。而右邊相當于從另一篇文章里抽取的又一個圖譜。這兩個圖譜有些相似但又不同,他們有不同的數據來源,尤其一些常見的實體,網上有成千上萬的網頁和它有關,能抽取非常多的知識,這時候要做知識的融合,甚至有一些數據可能帶來錯誤,不管是原始數據的錯誤還是分析過程中的錯誤,都要校驗,最后保證知識圖譜的質量。
再舉一個行業知識圖譜的例子,這是電信行業某一個運營商的手機流量套餐。和流量套餐相關的會有很多聯接,比如日流量、月流量、流量包等等,可以建這樣的圖譜。同時,對于一個行業來講,除了它靜態的實體、屬性、關系以外,還有業務邏輯。比如你打一個運營商的客服電話,想辦流量包,他會問你是什么包,全國包還是本地包等等。你選擇了其中一個以后,要查流量或者其他服務,又是一個完整的流程。這個流程實際上組成行業知識圖譜的一部分。結合左邊的圖和右邊的流程,我們就完成了一個運營商自動的客服。現在大家打到運營商某個客服電話,有一定比例其實是在和百度的智能客服機器人對話。
剛才講的是一些基本的圖譜應用,再講一個帶有一定推理色彩的。比如我們問今天離圣誕節還有幾天。這樣的問題對人來講不是很難,對知識圖譜而言,這就不是一個靜態的知識,我們無法把這個問題的答案直接存在圖譜里,而是需要先把今天是幾號搞清楚,圣誕節是哪一天搞清楚,然后做個簡單的計算得到一個正確的答案。
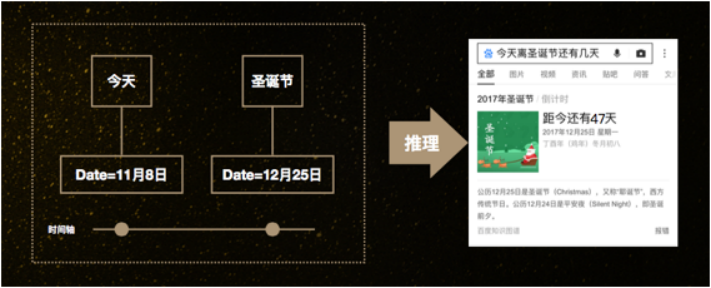
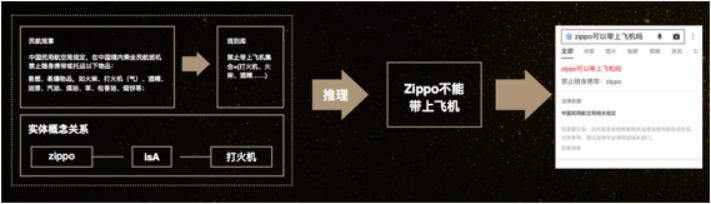
而右邊的更復雜一點,用戶的問題是,“Zippo能不能帶上飛機”。我們需要先在知識圖譜里知道Zippo是打火機,而民航規定打火機是不允許帶的,這時候再推理一步就得到最終的答案,坐飛機是禁止帶Zippo的。
百度很早就在做知識圖譜了,真正大規模上線是2014年,到今年三年時間,這個曲線一直在飛速地增長,長了大概160倍,說明百度搜索這樣的應用越來越依賴知識圖譜。
傳統的搜索是搜索一個內容,主流搜索引擎一頁給10個結果。有了知識圖譜的支撐,我們可以給用戶更直接的答案,并以一種更友好的方式呈現。比如第一個例子是搜索“胡歌”,大家看到圖文并茂的結果,需要的常用信息放在這兒。第二個問“太陽的重量”,雖然網頁也能找到,但不如直接把重量給出來。最右邊的例子是用戶搜索“孫儷”,除了給一些孫儷的信息出來,還會有相關的人、作品等等。我們把相關的影視作品推薦出來,用戶可能感興趣,比如《那年花開月正圓》,在界面一點就可以進入《那年花開月正圓》的頁面。
漢語語言本身非常博大精深,有專門針對漢語語言的知識圖譜,比如問“凹凸的凹,筆順。”這個字我相信每個人都會寫,但是不是每個人都能寫對筆順呢?知識圖譜可以直接把筆順告訴大家。我們現在大多用拼音輸入法和語音輸入,一些字不會念,也沒法拼音輸入。針對中文,我們會把漢字拆解,用語言描述它。比如,如果不知道“懟”字怎么念,我們就可以這樣提問,“上面是對下面是心怎么念。”家里有學生的朋友可能會比較關心這個問題,比如要查美好的“好”字的多音字詞組,或者成語等等,知識圖譜可以直接列出來。
屏幕上是我們根據新智元曾經發表的一篇文章,分析這篇文章里面提到的關鍵詞語和關鍵實體,組成的一個圖譜。文章由此被打上標簽。比如主題標簽是“人工智能”,話題標簽是“深度學習”等等,還有加上其他標簽。我們對用戶也有自己的模型,知道他關心什么領域,關心什么話題,有了兩者的標簽,我們就可以把合適的文章推薦給合適的用戶。比如這個用戶的畫像是“IT精英”、“互聯網”等等,新智元這篇文章可能正好是這個用戶所喜歡的。
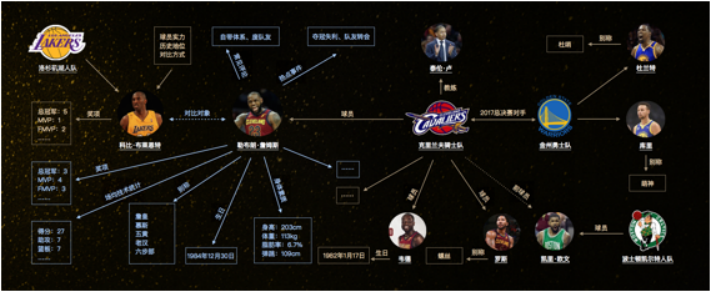
再舉一個NBA的例子。NBA很著名的球員,比如詹姆斯、庫里等等,他們之間有各種關系,不只是和現在球隊之間的關系,比如他的基本信息,身高、體重、成就等等。很多人把詹姆斯和科比做對比,這個對比在圖里也能看到。用戶有時會在一些產品里提問,比如問詹姆斯取得了什么成就,和科比對比等等。機器之所以能回答這些問題,是因為背后有這些知識。所以,一輪一輪,機器和人之間就交流下去了。
我上中學的時候在看1983版的《射雕》,現在有了最新的2017版《射雕》。我們現在知道這個視頻是新《射雕》,它的主題曲是《鐵血丹心》。當我們問類似的視頻是什么,就能找到1983版的《射雕》。知識圖譜會縱橫交錯把各種信息關聯起來,不管現在還是歷史的。1983版的郭靖是黃日華演的,如果問黃日華其他作品,就能看到《天龍八部》;如果問這部書的作者是誰,就會找到金庸先生。一步步延伸下去,相當于在這樣巨大的圖里暢游,每個用戶關心的方向不一樣,往任何方向都可以不斷地延展下去。
剛才講了一些應用的例子,從搜索到對話,到推薦等等。雖然這次人工智能的爆發很大程度上和互聯網關系很大,但人工智能影響的遠遠不止是互聯網行業,它會影響到各行各業,深入到我們工作和生活中的方方面面。這次十九大報告也指出,將互聯網、大數據、人工智能這些技術與實體經濟深度融合,包括工業、農業、金融等領域。融合的過程中,人工智能要想為這些行業有更好的服務,需要對這些行業進行定制化,要有行業的知識,這時候在通用知識的圖譜上也就進而要有行業的知識圖譜,幫助這些行業提升生產力,幫助這些行業和產業去升級。
最后,我想總結一下。我們通過AI技術和大量的數據、以及與用戶的互動不斷地學習,匯集越來越多的知識,這些知識不僅包括通用的知識,也包括行業的知識,進而更好地理解世界,從而讓我們用人工智能來提升我們的產品,提升每一個行業,讓我們的生活變得更加美好。



