2020年,“新基建”正給中國科技發展帶來新的重大機遇,人工智能基礎設施面臨全面升級。深度學習框架正是推動產業智能化進階的重要基礎設施。近日,國內唯一開源開放、功能完備的深度學習開源平臺——百度飛槳,在智能視覺領域實現重大升級。
此次,PaddleCV 最新全景圖首度曝光。其中:PaddleDetection、PaddleSeg、PaddleSlim 和 Paddle Lite 重磅升級;全新發布 3D 視覺和 PLSC 超大規模分類2項能力。同時,PaddleCV 新增了15個在產業實踐中廣泛應用的算法,整體高質量算法數量達到73個;35個高精度預訓練模型,總數達到203個。
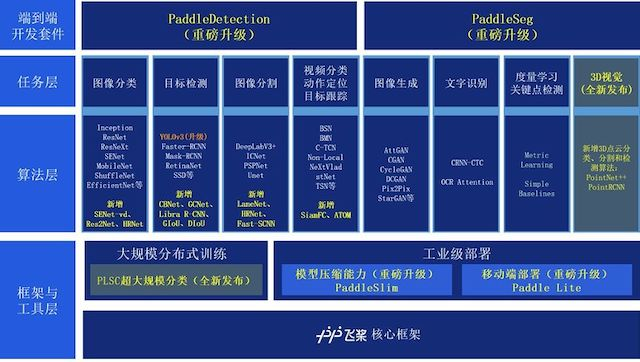
▲ PaddleCV 全景圖
PaddleCV 依托于飛槳底層核心技術以及百度大腦軟硬一體 AI 大生產平臺的優勢,貫通了從核心技術、生態應用,再到商業化解決方案的整套體系,支撐百度視覺成為目前業內規模最大、技術棧最全面、生態體系最完善的視覺技術平臺,形成可自我持續迭代優化的閉環。
如全景圖所示,PaddleCV 主要從三方面更新核心技術能力:

核心技術能力升級,基于產業實踐真實場景打磨,多場景視覺任務上模型準確率全面提升。
PaddleDetection 模塊種類與性能全面提升,YOLOv3 大幅增強,精度提升4.3%,訓練提速40%,推理提速21%;人臉檢測模型 BlazeFace 新增 NAS 版本,體積壓縮3倍,推理速度提速122%;新增 IoU 損失函數類型,精度再提升1%,不增加預測耗時。
在模型方面,新增3個類型,基于 COCO 數據集的精度最高開源模型 CBNet,高達53.3%;Libra-RCNN 模型精度提升2%;Open Images V5 成為目標檢測比賽最佳單模型。
PaddleSeg 新增基于 HRNet 的高精度圖像分割模型,其最大的特點是將圖像在整個處理過程中保持高分辨率特征,這和大多數模型所使用的從高分辨率到低分辨率網絡產生的低分辨率特征中恢復高分辨率特征有所不同。同時,獲得實時語義分割模型 Fast-SCNN,它的最大特點是“小快靈”,即該模型在推理計算時僅需要較小的 FLOPs,就可以快速推理出一個不錯的結果。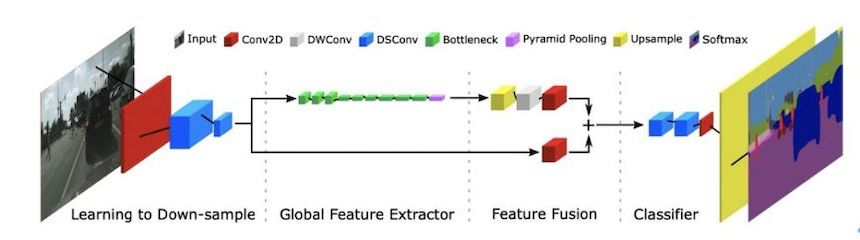
▲ Fast-SCNN 網絡結構圖
PaddleCV 還新增了 3D 點云分類、分割和檢測的 PointNet++ 和 PointRCNN 模型。PointNet++ 在 ModelNet40 數據集上,分類精度高達90%;PointRCNN 在 KITTI(Car)的 Easy 數據子集上,檢測精度高達86.66%。和此前 PaddleCV 支持的數十種模型一樣,基于飛槳框架,開發者無需全新開發代碼,只要進行少量修改,就能快速在工業領域實現 3D 圖像的分類、語義分割和目標檢測任務。
圖像分類新增預訓練模型 SENet-vd、Res2Net、HRNet 系列模型。Res2Net 可以更細粒度表示多尺度特征,HRNet 全程都可以保持高分辨率。截至目前,飛槳圖像分類模型包含了 ResNet、ResNet-vd、ResNet_ACNet、MobileNet、ShuffleNet、EfficientNet 等系列近20類圖像分類算法,105個預訓練模型,也可供目標檢測、圖像分割等任務應用。其中,ResNet-vd 系列相比 ResNet 系列模型,在不增加推理耗時的情況下,精度提高1%-2%,EfficientNet 推出了 small 版本,在 GPU 上速度提升1.59倍。

PaddleCV 端到端能力大幅提升,打通了模型開發、訓練、壓縮、部署全流程,更好地服務于產業實踐。
目標檢測模型在實際部署時,由于耗時和內存占用,仍然存在很大挑戰。基于此,PaddleSlim 提供了多種高效的模型壓縮方法,助推 PaddleDetection 性能到達全新高度。使用蒸餾模型壓縮方案可提升驗證精度2%;裁剪模型壓縮方案大幅降低 FLOPs;蒸餾+裁剪模型壓縮方案,基于 COCO 數據集進行測試,可以加速2.3倍。此外,PaddleDetection 還為開發者提供了從訓練到部署的端到端流程,并提供一個跨平臺的圖像檢測模型的 C++ 預測部署方案。
跟目標檢測模型類似,語義分割模型在實際部署時也會面臨耗時、內存占用的挑戰。PaddleSlim 為 PaddleSeg 提供了多種分割模型的壓縮方案,FLOPs 減少51%,提升部署成功率。
針對超大規模人臉識別等應用挑戰,正式發布 PLSC 超大規模分類工具。
一方面,通過多機分布式訓練可以將全連接層參數切分到更多的 GPU 卡,從而支持千萬類別分類,并且飛槳大規模分類庫在理論上可支持分類類別數隨著使用 GPU 卡數的增加而增加。
另一方面,PLSC 的訓練精度和效率高,在多個數據集上得 SOTA 的訓練精度,同時支持混合精度訓練,單機8張 Nvidia Tesla v100 GPU 配置下混合精度訓練速度提升42%。
PLSC 讓開發者通過五行代碼即可實現千萬類別分類網絡的構建和訓練,提供大規模分類任務從訓練到部署的全流程解決方案。同時,支持訓練 GPU 卡數的動態調整、Base64 格式圖像數據預處理。
PaddleCV 與飛槳領先分布式訓練能力全面結合,對于人臉識別等廣泛的場景應用提供了強有力的推動作用。3月初,百度開源的“戴口罩人臉識別算法”中,即通過 PLSC 實現了快速對數百萬 ID 的訓練數據進行訓練;同時采用飛槳模型壓縮庫 PaddleSlim 進行模型搜索與壓縮,產出了高性能的人臉識別模型;最后基于 PaddleLite,實現了云端和移動端的快速部署。

PaddleCV 全面打通了模型算法、開發框架和 AI 芯片,實現軟硬一體化。
首先,PaddleCV 基于 Paddle Lite 多硬件支持能力的優勢,與昆侖芯片進行深度聯合優化,實現端到端軟硬一體能力的完全領先和自主可控。以制造業為例,百度與微億智造聯合打造了智能自動化監測設備“表面缺陷視覺檢測設備”,區別于傳統人工肉眼檢查電子零件的方式,既保障質檢環節的檢查質量與效率,也進一步緩解了由于疫情原因造成的人力缺乏問題。
此次合作,借由百度昆侖芯片、百度智能云的加持,以及基于百度飛槳深度學習平臺的目標檢測模型,微億構建完成了一個從智能硬件到算法軟件再到算力供給的智能制造解決方案大閉環,具備了端到端軟硬一體能力,實現了完全的自主可控。
此外,在央視《新聞聯播》2月10日報道中還提到,江蘇常州的精研科技借助“表面缺陷視覺檢測設備”,解決了工人無法復工情況下的生產難題,在精研科技的精密零部件制造車間,十臺無人值守的智能化檢測設備24小時工作,比人工檢測效率提升近10倍。

▲ 百度與微億智造打造的工業智能質檢設備
PaddleCV 的重磅升級,飛槳為視覺領域提供了更為強大且應用廣泛的工具,加速不同產業的 AI 落地。除了在視覺領域,飛槳也形成了語音、視覺、NLP 等全方位的能力體系。飛槳還充分發揮全硬件平臺能力的優勢,與昆侖芯片深度融合優化,打造技術領先、自主可控的軟硬一體技術平臺。
目前,飛槳已累計服務150多萬開發者,幫助6.5萬企業用戶,作為百度大腦的堅實底座,在很多關乎國計民生的領域,都發揮著實實在在的重要作用。



