
近日,IEEE 國際計算機視覺與模式識別會議CVPR 2021年度論文錄用結果公布。作為全球計算機視覺三大頂會之一的CVPR,此次共收錄7015篇有效投稿,最終有1663篇突出重圍,接受率為23.7%;據悉,近兩年CVPR錄用結果均在25%左右,2020年更是降至22.1%,錄用愈發嚴格。百度今年繼續保持高質量輸出,貢獻了多篇計算機視覺相關的優質論文,涵蓋圖像語義分割、文本視頻檢索、3D目標檢測、風格遷移、視頻理解、遷移學習等多個研究方向,這些技術創新和突破將有助于智慧醫療、自動駕駛、智慧城市、智慧文娛、智能辦公、智慧制造等場景的落地應用,進一步擴大中國AI技術的影響力,推進全球人工智能的發展。
此外,百度今年也聯合澳大利亞悉尼科技大學和美國北卡羅來納大學舉辦CVPR 2021 NAS Workshop(https://www.cvpr21-nas.com/),并已啟動了相應的國際競賽(https://www.cvpr21-nas.com/competition),探索神經網絡結構中的搜索效率和效果問題。當前,來自全球的參賽隊伍已超過400支。
以下為百度CVPR2021部分精選論文的亮點集錦。
1.一種快速元學習更新策略及其在有噪聲標注數據上的應用
Faster Meta Update Strategy for Noise-Robust Deep Learning
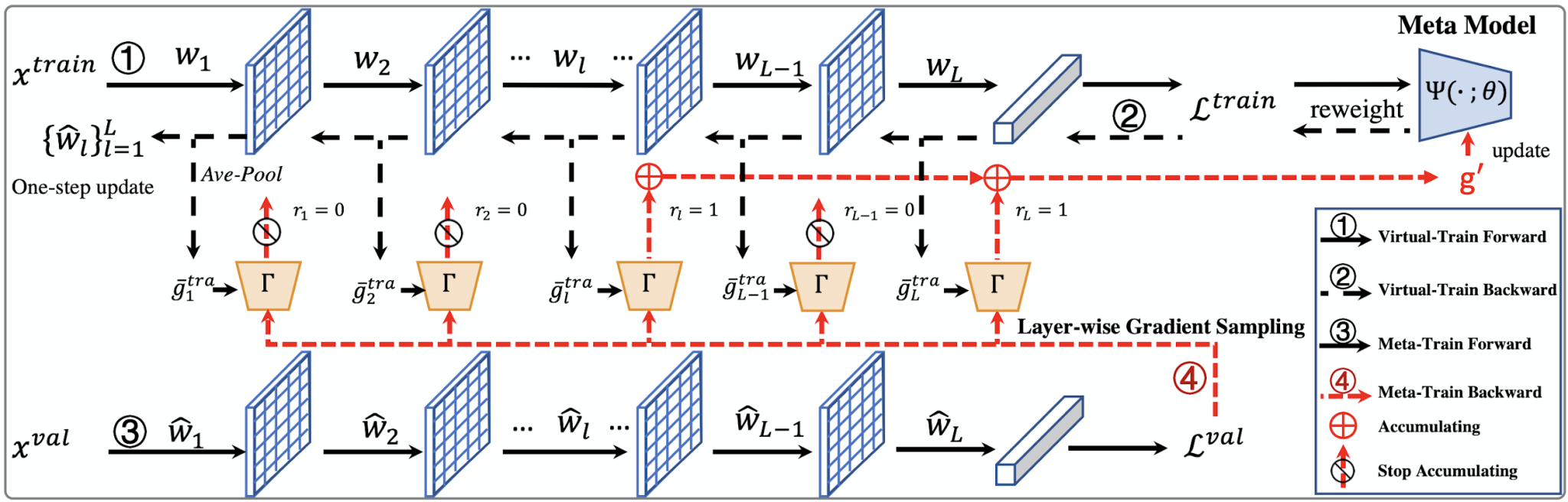
本論文已被CVPR2021接收為oral論文。基于meta-learning的方法在有噪聲標注的圖像分類中取得了顯著的效果。這類方法往往需要大量的計算資源,而計算瓶頸在于meta-gradient的計算上。本文提出了一種高效的meta-learning更新方式:Faster Meta Update Strategy (FaMUS),加快了meta-learning的訓練速度 (減少約2/3的訓練時間),并提升了模型的性能。首先,本文發現meta-gradient的計算可以轉換成一個逐層計算并累計的形式; 并且,meta-learning的更新只需少量層數在meta-gradient就可以完成。基于此,本文設計了一個layer-wise gradient sampler 加在網絡的每一層上。根據sampler的輸出,模型可以在訓練過程中自適應地判斷是否計算并收集該層網絡的梯度。越少層的meta-gradient需要計算,網絡更新時所需的計算資源越少,從而提升模型的計算效率。并且,本文發現FaMUS使得meta-learning更加穩定,從而提升了模型的性能。本文在有噪聲的分類問題以及長尾分類問題都驗證了本文方法的有效性。最后,在實際應用中,本文的方法可以擴展到大多數帶有噪聲標注數據的場景或者任務中,減少了模型對于高質量標注數據的依賴,具有較為廣闊的應用空間。
2.面向無監督域適應圖像語義分割的具有域感知能力的元損失校正方法
MetaCorrection: Domain-aware Meta Loss Correction for Unsupervised Domain Adaptation in Semantic Segmentation
論文鏈接: https://arxiv.org/abs/2103.05254
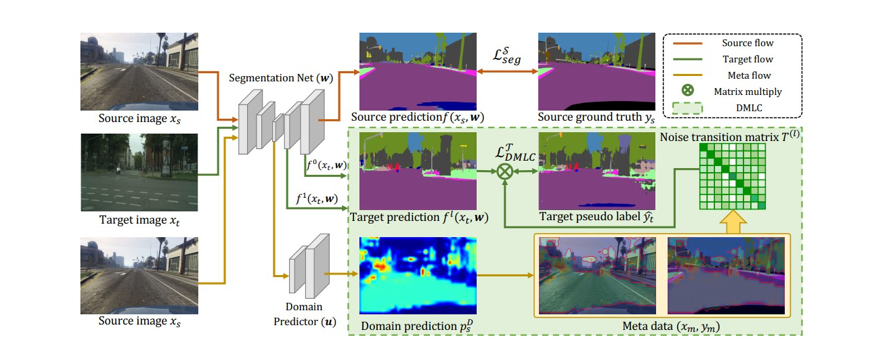
無監督域適應在跨域圖像語義分割問題上取得了不錯的效果。已有的基于自訓練(self-training)方式的無監督域適應方法,通過對目標域分配偽標簽來達到較好的域適應效果,但是這些偽標簽不可避免的包含一些標簽噪聲。為了解決這一問題,本研究提出了“元校正”的新框架,該新框架利用域可知的元學習(Meta Learning)方式來促進誤差校正。首先把包含噪聲標簽的偽標簽通過一個噪聲轉移矩陣進行表達,然后通過在構建的元數據上,對此噪聲轉移矩陣進行優化,從而提高在目標域的性能。該新方案在GTA5→CityScapes、SYNHIA→CityScapes 兩個標準自動駕駛場景數據庫及Deathlon→NCI-ISBI13醫學圖像數據庫跨域分割測試上都取得了非常不錯的結果。該方案以后有望在自動駕駛圖像及醫學圖像分割上取得落地。
3.基于跨任務場景結構知識遷移的單張深度圖像超分辨率方法
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
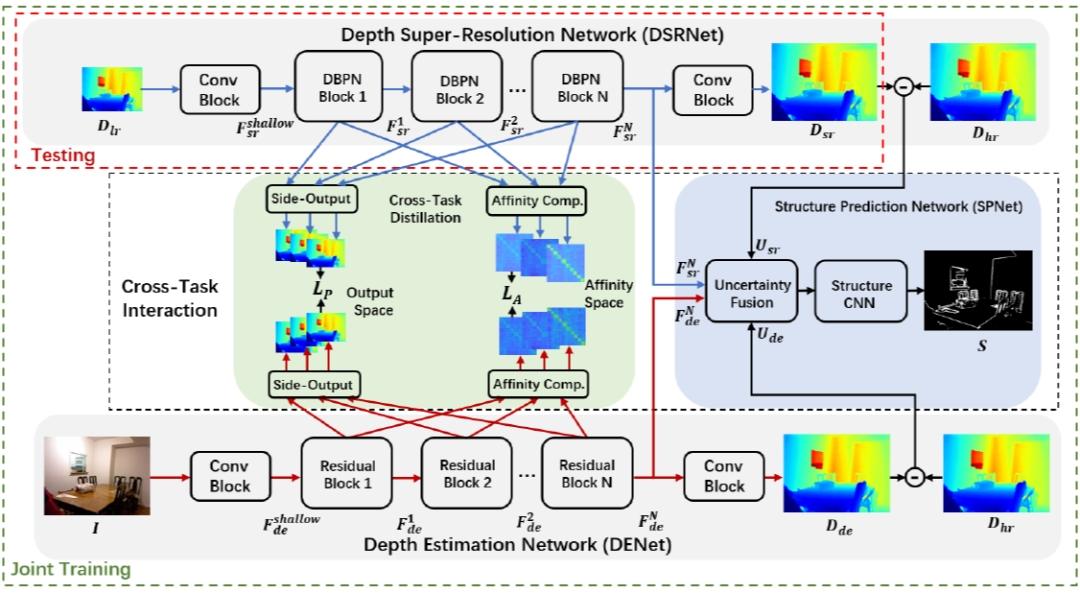
本項研究針對深度傳感系統獲取的場景深度圖像分辨率低和細節丟失等問題,突破現有基于彩色指導的場景深度復原方法的局限性,首次提出基于跨任務場景結構知識遷移的單一場景深度圖像超分辨率方法,在訓練階段從彩色圖像蒸餾出場景結構信息來輔助提升深度復原性能,而測試階段僅提供單張降質深度圖像作為輸入即可實現深度圖像重建。該算法框架同時構造了深度估計任務(彩色圖像為輸入估計深度信息)及深度復原任務(低質量深度為輸入估計高質量深度),并提出了基于師生角色交換的跨任務知識蒸餾策略以及不確定度引導的結構正則化學習來實現雙邊知識遷移,通過協同訓練兩個任務來提升深度超分辨率任務的性能。
在實際部署和測試中,所提出的方法具有模型輕量化、算法速度快等特點,且在缺少高分辨率彩色信息輔助的情況下仍可獲得優異的性能。此項研究能有效應用于機器人室內導航及自動駕駛等領域。
4. 基于拉普拉斯金字塔網絡的快速高質量藝術風格遷移
Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer

藝術風格遷移是指將一張風格圖中的顏色和紋理風格遷移到一張內容圖上,同時保存內容圖的結構。相關算法在藝術圖像生成、濾鏡等領域有廣泛的應用。目前基于前饋網絡的風格化算法存在紋理遷移不干凈、大尺度復雜紋理無法遷移等缺點;而目前基于優化的風格化方法雖然質量較高,但速度很慢。因此本文提出了一種能夠生成高質量風格化圖的快速前饋風格化網絡——拉普拉斯金字塔風格化網絡(LapStyle)。本文在實驗中觀察到,在低分辨率圖像上更容易對結構復雜的大尺度紋理進行遷移,而在高分辨率圖像上則更容易對局部小尺度紋理進行遷移。因此本文提出的LapStyle首先在低分辨率下遷移復雜紋理,再在高分辨率下對紋理的細節進行修正。在實驗中,LapStyle遷移復雜紋理的效果顯著超過了現有方法,同時能夠在512分辨率下達到100fps的速度。本文的方法能夠給用戶帶來新穎的體驗,同時也能夠實現移動端上的實時風格化效果。
5.一種通用的基于渲染的三維目標檢測數據增強框架
LiDAR-Aug: A General Rendering-based Augmentation Framework for 3D Object Detection
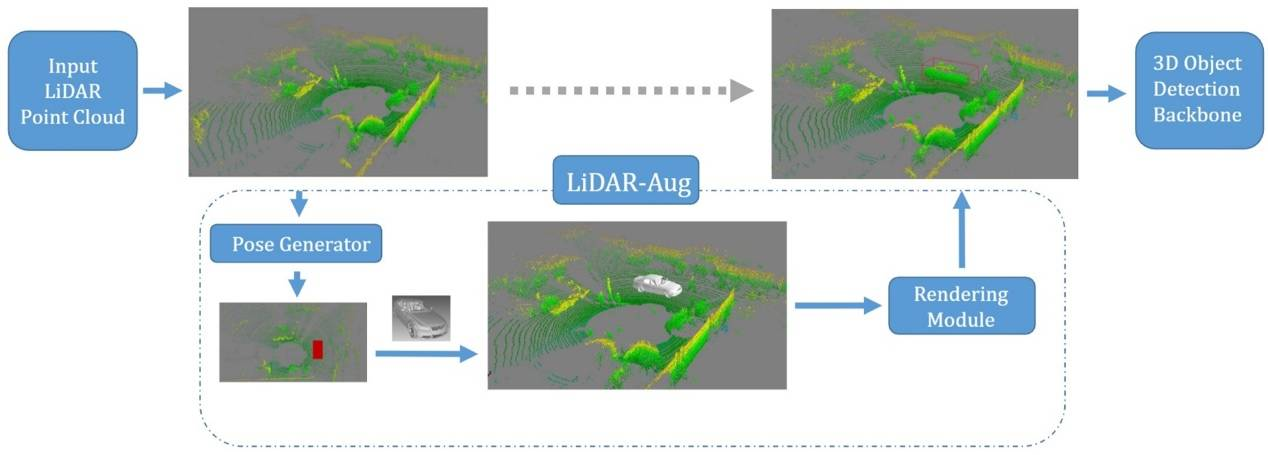
在自動駕駛中,感知模塊非常重要,直接影響著后續的物體跟蹤、軌跡預測、路徑規劃等模塊。現在主流的三維目標檢測算法都是基于深度學習。而對于基于深度學習的三維目標檢測任務而言,帶有標注信息的激光雷達點云數據非常關鍵。但是數據標注,尤其是基于點云的三維標注,本身成本高昂且耗時久,而數據增強則可以作為一個在模型訓練階段的一個重要的模塊,來減緩對于數據標注的需求。在三維目標檢測領域中,簡單的將物體進行復制粘貼是一種非常常見的數據增強策略,但是往往忽略了物體之間的遮擋關系。為了解決這個問題,本文提出了一種基于計算機圖形學渲染的激光雷達點云數據增強框架,LiDAR-Aug,來豐富訓練數據從而提升目標檢測的性能。
本文提出的數據增強模塊使用即插即用的方式,可以很容易的集成到常見的目標檢測框架中。同時,本文的增強算法對于檢測算法適用性很廣,可用于基于網格劃分、基于柱狀深度圖表示等等檢測算法中。比起常見的其他三維目標檢測數據增強方法,本文的方法生成的增強數據,具有更廣的多樣性和真實感。最后,實驗結果表明,本文提出的方法可以應用在主流的三維目標檢測框架上,給自動駕駛的感知系統帶來檢測性能的提升,尤其是對于稀缺場景和類別,能帶來較大的提升。
6.基于細粒度自適應對齊的文本視頻檢索
T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval
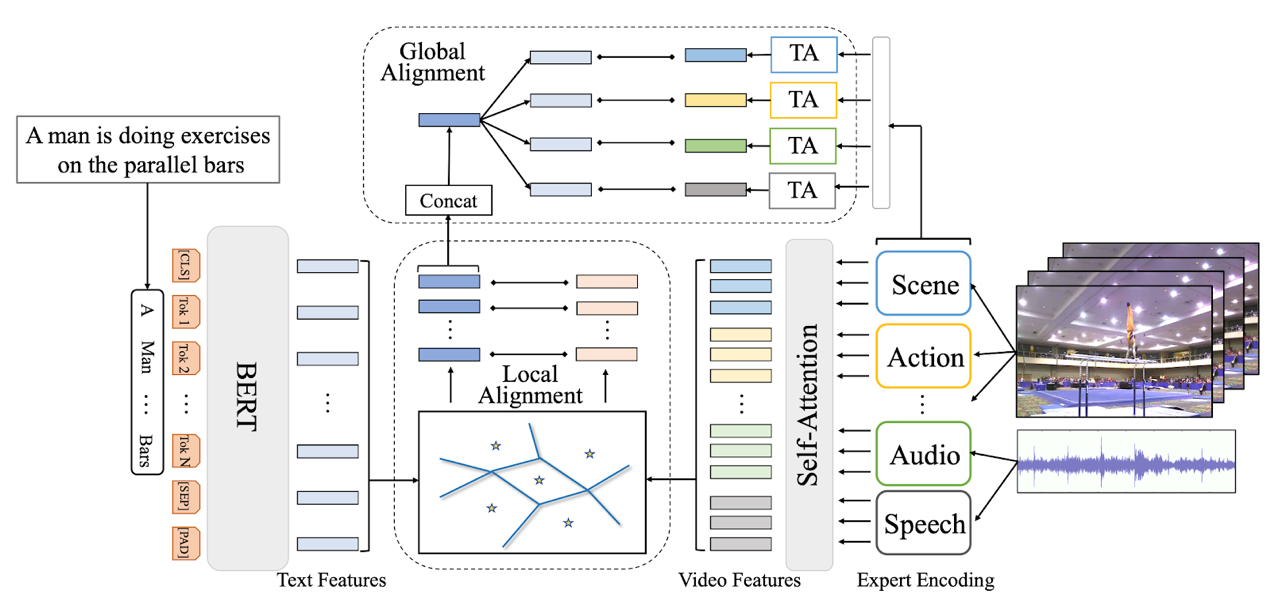
隨著互聯網視頻尤其是短視頻的火熱,文本視頻檢索在近段時間獲得了學術界和工業界的廣泛關注。在引入多模態視頻信息后,如何精細化地配準局部視頻特征和自然語言特征成為這一問題的難點。本文提出自動化學習文本和視頻信息共享的語義中心,并對自適應聚類后的局部特征做對應匹配,避免了復雜的計算,同時賦予了模型精細化理解語言和視頻局部信息的能力。此外,本文的模型可以直接將多模態的視頻信息(聲音、動作、場景、speech、OCR、人臉等)映射到同一空間,利用同一組語義中心來做聚類融合,在一定程度上解決了多模態信息難以綜合利用的問題。本文的模型在三個標準的Text-Video Retrieval Dataset上均取得了SOTA。對比Google在ECCV 2020上的發表的最新工作,本文的模型能在將運算時間降低一半的情況下,僅利用小規模標準數據集,在兩個benchmark上超過其在億級視頻文本數據(Howto100M)上pretrain模型的檢索結果。
7.VSPW:大規模自然視頻場景分割數據集
VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild
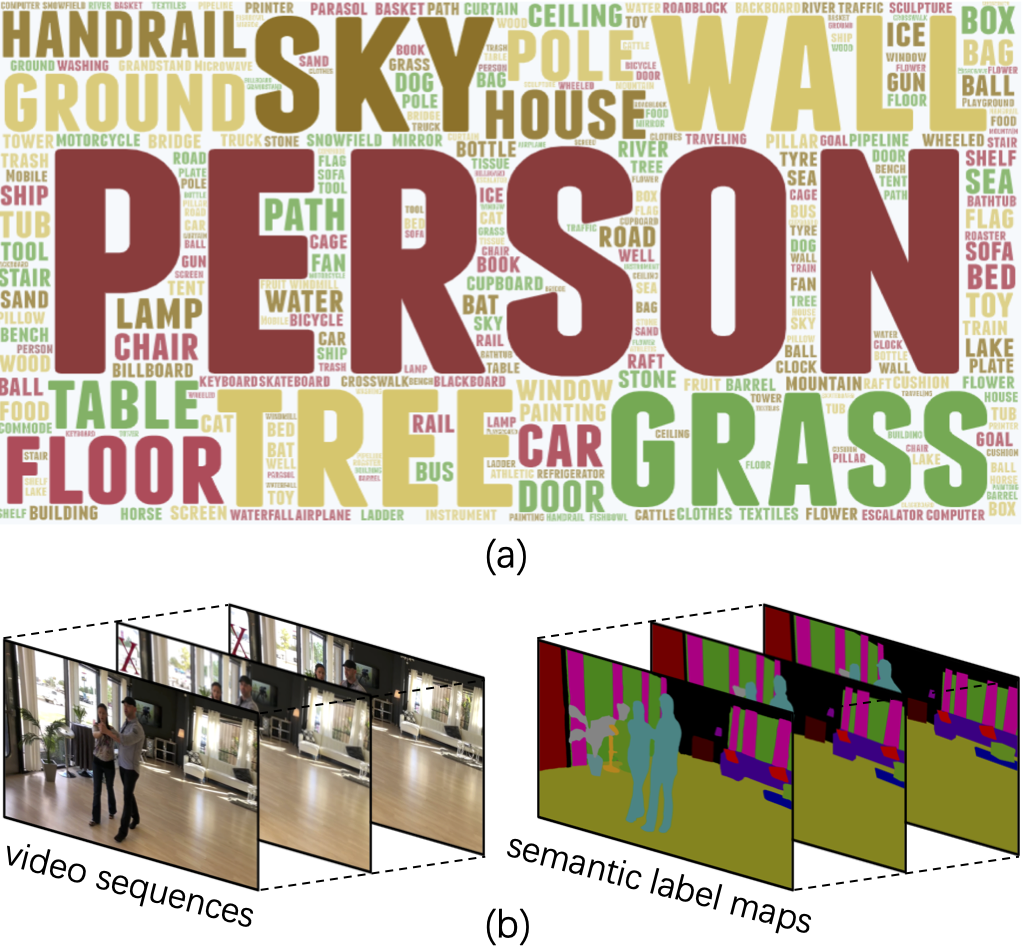
近年來,圖像語義分割方法已經有了長足的發展,而對視頻語義分割的探索比較有限,一個原因是缺少足夠規模的視頻語義分割數據集。本文提出了一個大規模視頻語義分割數據集,VSPW。VSPW數據集有著以下特點:(1)大規模、多場景標注:本數據集共標注3536個視頻、251632幀像素級語義分割圖片,涵蓋了124個語義類別,標注數量遠超之前的語義分割數據集(Cityscapes, CamVid)。與之前數據集僅關注街道場景不同,本數據集覆蓋超過200種視頻場景,極大豐富了數據集的多樣性;(2)密集標注:之前數據集對視頻數據標注很稀疏,比如Cityscapes,在30幀的視頻片段中僅標注其中一幀。VSPW 數據集按照15f/s的幀率對視頻片段標注,提供了更密集的標注數據;(3)高清視頻標注:本數據集中,超過96%的視頻數據分辨率在720P至4K之間。與圖像語義分割相比,視頻語義分割帶來了新的挑戰,比如,如何處理動態模糊的幀、如何高效地利用時序信息預測像素語義、如何保證預測結果時序上的穩定等等。
本文提供了一個基礎的視頻語義分割算法,利用時序的上下文信息來提升分割精度和穩定性。同時,本文還提出了針對視頻分割時序穩定性的新的度量標準。期待VSPW 能促進針對視頻語義分割領域的新算法不斷涌現,解決上文提出的視頻語義分割帶來的新挑戰。
8.基于視覺算法一次性去除雨滴和雨線
Removing Raindrops and Rain Streaks in One Go
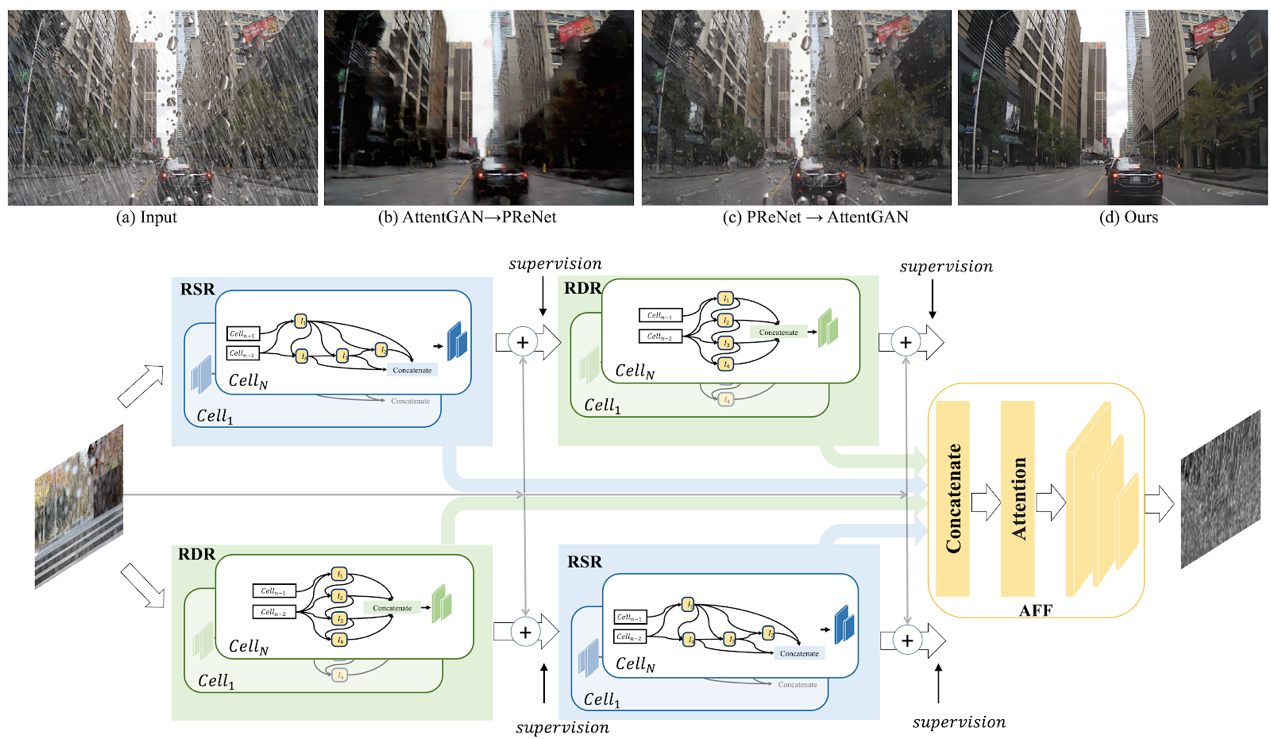
現有的去雨算法一般針對的是單一的去除雨線或者是去除雨滴問題,但是在現實場景中兩種不同類型的雨往往同時存在。尤其是在下雨的自動駕駛場景中,空氣中線條狀的雨線和擋風玻璃上的橢圓形水滴都會嚴重影響車載攝像頭捕捉的畫面的清晰度,從而大幅降低了自動駕駛視覺算法的準確性。針對這一問題,本文首先設計一種互補型級連網絡結構—CCN,能夠在一個整體網絡中以互補的方式去除兩種形狀和結構差異較大的雨。其次,目前公開數據集缺少同時含有雨線和雨滴的數據,對此本文提出了一個新的數據集RainDS,其中包括了雨線和雨滴數據以及它們相應的Ground Truth,并且該數據集同時包含了合成數據以及現實場景中拍攝的真實數據以用來彌合真實數據與合成數據之間的領域差異。實驗表明,本文的方法在現有的雨線或者雨滴數據集以及提出的RainDS上都能實現很好的去雨效果。在實際應用中,使用一個整體的網絡同時去除視野中的雨滴和雨線,可進一步幫助提升在下雨天氣中自動駕駛視覺算法的準確性。
9.弱監督聲音-視頻解析中的異類線索探索
Exploring Heterogeneous Clues for Weakly-Supervised Audio-Visual Video Parsing
現有的音視頻研究常常假設聲音和視頻信號中的事件是天然同步的,然而在日常視頻中,同一時間可能音視頻會存在不同的事件內容。比如一個視頻畫面播放的是足球賽,而聲音聽到的是解說員的話音。本文旨在精細化的研究分析視頻中的事件,從視頻和音頻中分析出事件類別和其時間定位。本文針對通用視頻,設計一套框架來從弱標簽中學習這種精細化解析能力。該弱標簽只是視頻的標簽(比如籃球賽、解說),并沒有針對音視頻軌道有區分標注,也沒用時間位置標注。本文使用MIL(Multiple-instance Learning)來訓練模型。然而,因為缺少時間標簽,這種總體訓練會損害網絡的預測能力,可能在不同的時間上都會預測同樣的事件。因此本文提出引入跨模態對比學習,來引導注意力網絡關注到當前時刻的底層信息,避免被全局上下文信息主導。此外,本文希望能精準地分析出到底是視頻還是音頻中包含這個弱標簽信息。因此,本文設計了一套通過交換音視頻軌道來獲取與模態相關的標簽的算法,來去除掉模態無關的監督信號。具體來說,本文將一個視頻與一個無關視頻(標簽不重合的視頻)進行音視頻軌道互換。本文對互換后的新視頻進行標簽預測。如果他對某事件類別的預測還是非常高的置信度,那么本文認為這個僅存的模態軌道里確實可能包含這個事件。否則,本文認為這個事件只在另一個模態中出現。通過這樣的操作,本文可以為每個模態獲取不同的標簽。本文用這些改過的標簽重新訓練網絡,避免了網絡被模糊的全局標簽誤導,從而獲得了更高的視頻解析性能。該方法可以用來幫助精準定位愛奇藝等網絡視頻中的各類動作、事件。
10.基于雙尺度一致性的六自由度物體姿態估計學習
DSC-PoseNet: Learning 6DoF Object Pose Estimation via Dual-scale Consistency
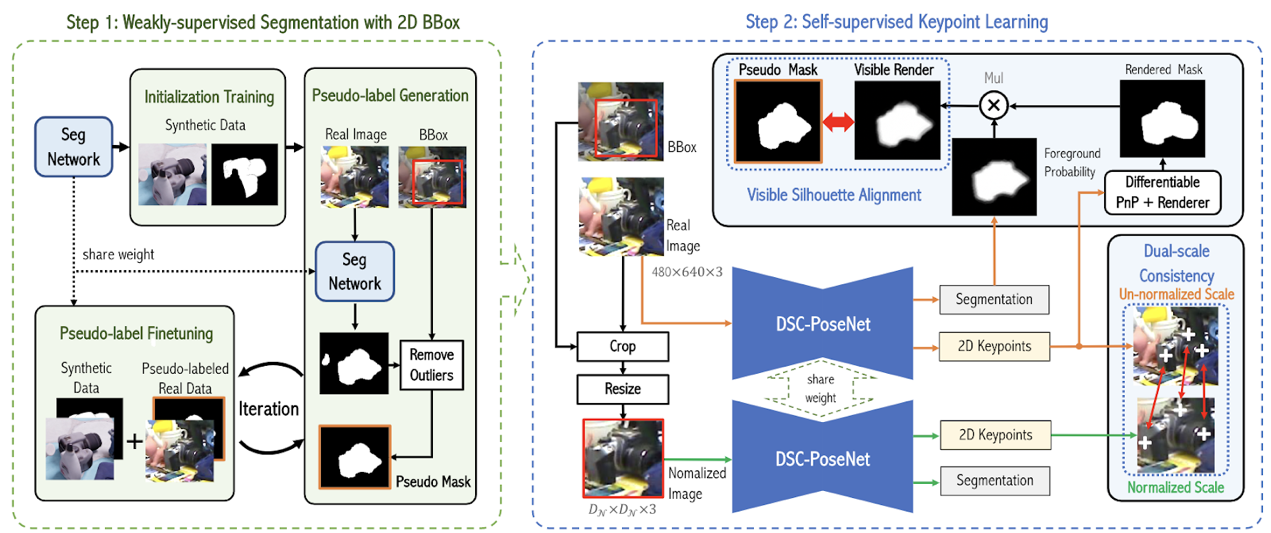
相比較于標注目標物體的二維外接框,人工標注三維姿態非常困難,特別是當物體的深度信息缺失的時候。為了減輕人工標注的壓力,本文提出了一個兩階段的物體姿態估計框架,從物體的二維外接框中學習三維空間中的六自由度物體姿態。在第一階段中,網絡通過弱監督學習的方式從二維外接框中提取像素級別的分割掩模。在第二階段中,本文設計了兩種自監督一致性來訓練網絡預測物體姿態。這兩種一致性分別為:1、雙尺度預測一致性;2、分割-渲染的掩模一致性。為驗證方法的有效性和泛化能力,本文在多個常用的基準數據集上進行了大量的實驗。在只使用合成數據以及外接框標注的條件下,本文大幅超越了許多目前的最佳方法,甚至性能上達到了許多全監督方法的水平。
11.基于深度動態信息傳播的單目3D檢測
Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection
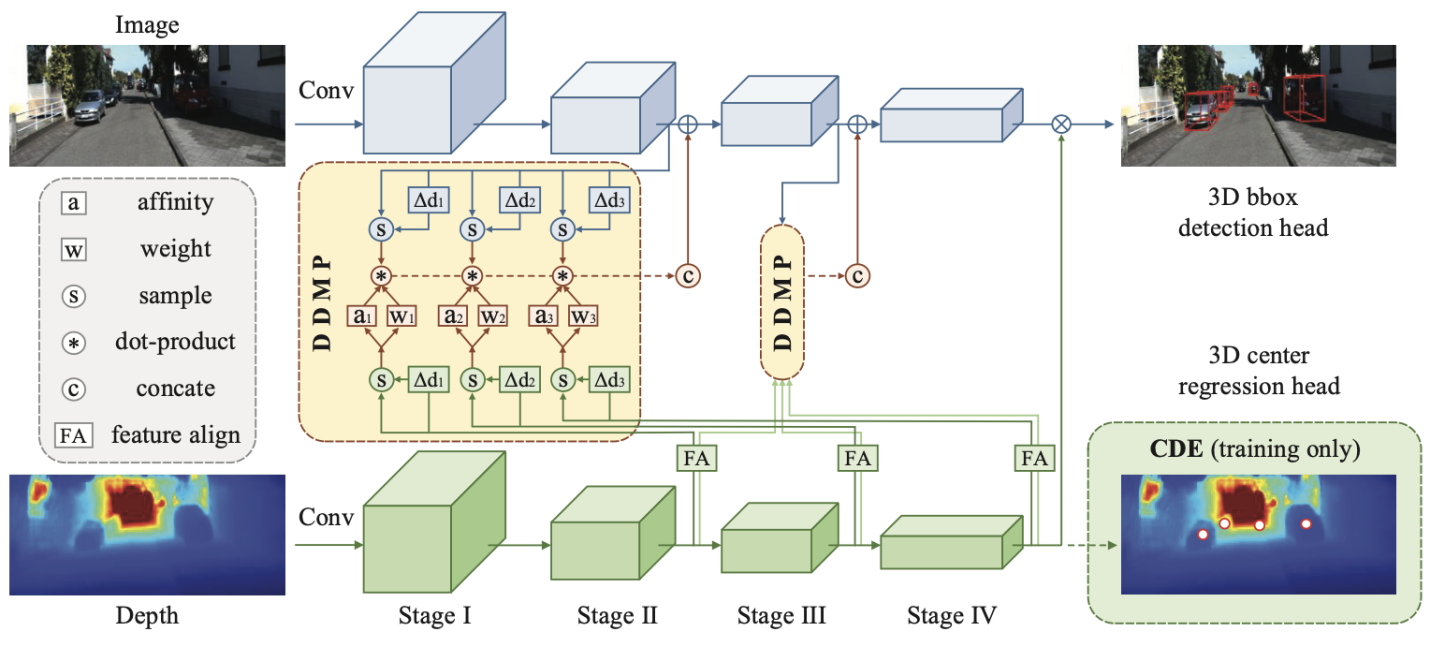
本文首次提出一種基于圖信息傳播模式的深度感知單目3D檢測模型(DDMP-3D),以有效的學習單目圖片3D目標的特征。具體來說,將每個特征像素視為圖中的一個節點,本文首先從特征圖中動態采樣一個節點的鄰域。通過自適應地選擇圖中最相關節點的子集,該操作允許網絡有效地獲取目標上下文信息。對于采樣的節點,本文模擬圖信息傳播模式,使用深度特征為節點預測濾波器權重和親和度矩陣,以通過采樣的節點傳播信息。此外,在傳播過程中探索了多尺度深度特征,學習了混合濾波器權重和親和度矩陣以適應各種尺度的物體。另外,為了解決先驗深度圖不準確的問題,本文增強了中心感知深度編碼(CDE)作為在深度分支處附加的輔助任務。它通過3D目標中心回歸任務,指導深度分支的中間特征具有中心感知能力,并進一步改善對象的定位。
這種基于單目的3D檢測模型對于設備的要求較低(僅需要單個攝像頭),容易在自動駕駛系統中實現應用。3D單目檢測作為自動駕駛系統中的第一步,為后續的物體識別、系統決策等一系列任務做基礎。
12.半監督遷移學習自適應一致性正則化
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
論文鏈接:https://arxiv.org/abs/2103.02193
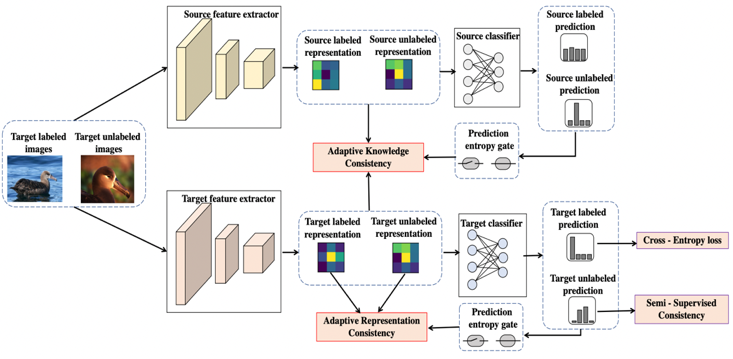
在標注樣本稀缺的情況下,半監督學習作為一種有效利用無標簽樣本,進而提供模型效果的技術,受到廣泛關注。預訓練加遷移學習的方式是另一種高效訓練優質模型的重要技術。本文研究了一個非常實用的場景,即在具備預訓練模型的情況下進行半監督學習。本文提出了自適應一致性正則化技術來充分利用預訓練模型和無標簽樣本的價值。具體的,該方法包含知識一致性(Adaptive Knowledge Consistency, AKC)和表征一致性(Adaptive Representation Consistency, ARC)兩個組件。AKC利用全部樣本保持預訓練模型和目標模型的知識一致性,來保障目標模型的泛化能力;而ARC要求在有標簽和無標簽的樣本之間保持表征的一致性,來降低目標模型的經驗損失。自適應技術在這兩項中用于選擇有代表性的樣本,以確保約束的可靠性。相比最新的半監督學習算法,本文的方法在通用數據集CIFAR-10/100,以及動物、場景、醫療三個特定領域的數據集上都獲得明顯的優勢,并且能和MixMatch/FixMatch等最新方法疊加使用獲得進一步提升,幾乎沒有額外的計算消耗。



